第一周
机器学习的定义
Tom Mitchell (1998) Well-posed Learning Problem: “A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E”.
对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么我们称这个计算机程序在从经验E学习
机器学习分类: 监督学习(Supervised learning)和无监督学习(Unsupervised learning)
监督学习
监督学习从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。训练集中的目标是由人标注的。常见的监督学习算法包括回归分析和统计分类。
回归问题,是在一个连续的输出上预测结果,即将输入映射到连续的输出函数,而分类问题,是在离散的输出上预测结果,即将输入映射到离散的类别。
无监督学习
与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有聚类
无监督学习允许我们在不知道或很少知道正确输出结果样式的情况下,从数据中获取结构,而且不需要了解各种变量对输出结果的影响。通过数据集群中数据变量间的关系,可以推导出结构。并且无监督学习不需要基于预测结果的反馈。
单变量线性回归模型
符号表示:
1. 表示输入变量,也叫作输入特征,上标i仅仅表示训练集中的第i个样本;
2. 表示输出变量,也叫作目标变量;
3. 表示一个训练样本;
4.m表示训练样本的个数, i=1,…,m。
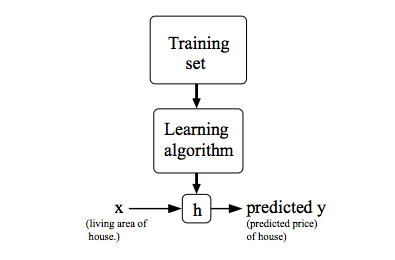
代价函数
函数h称作假设函数(hypothesis), 定义为: , 简写为: $h(x) = \theta_0 + \theta_1x$。这里使用线性函数,而没有使用非线性函数,因为线性函数最简单,因此先从线性函数入手, 之后再讨论更复杂的模型。这个线性模型被称为线性回归(linear regression)模型, 使用的是单变量$x$,也称作单变量线性回归。
那么如何选择 $\theta_0, \theta_1$ 使得h(x)接近于训练集中的输出变量$y$。通过定义代价函数$J(\theta_0, \theta_1)$,表示$h(x)$的准确性,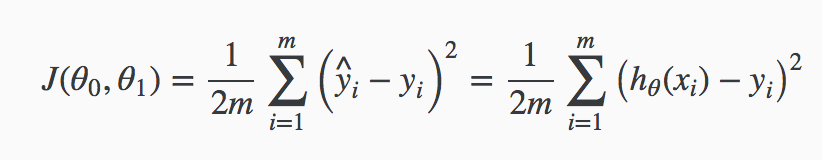
当$J(\theta_0, \theta_1)$取最小值时,获得最优$h(x)$函数。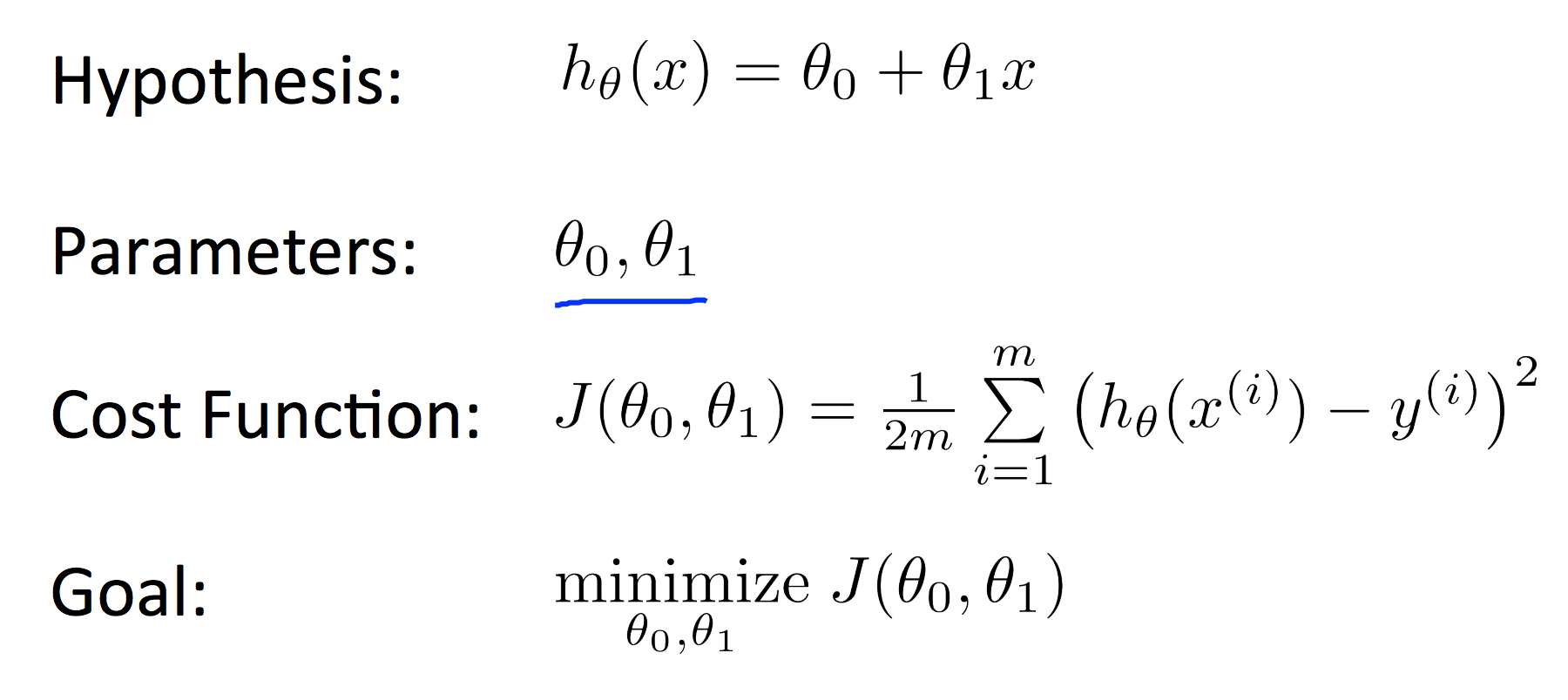
梯度下降算法
使用梯度下降算法寻找使得代价函数$J(\theta_0, \theta_1)$取得最小值时的解, 即$\theta_0, \theta_1$的值。
梯度下降算法不断重复下面过程,直到收敛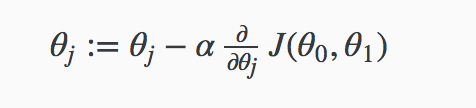
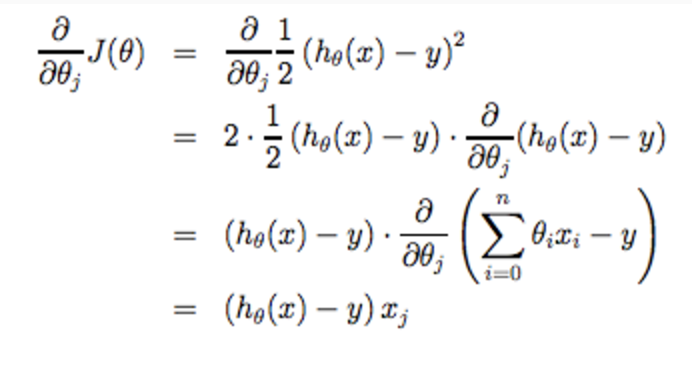

其中$j=0,1$, $\alpha$表示学习速率, 它控制我们以多大的幅度更新这个参数$\theta_j$; 每次迭代都必须同时更新$\theta_0, \theta_1$参数。
第二周
多变量线性回归
多特征
其中,表示样本的特征数。令$x_0=1$, 有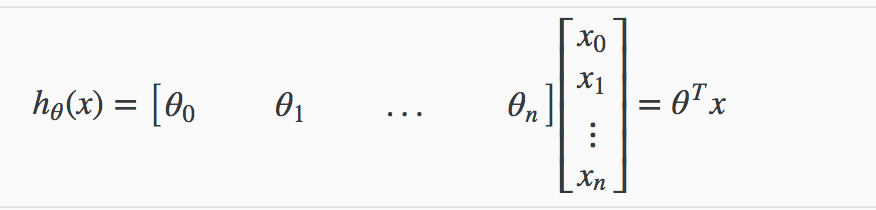
当只有3个样本,每个样本1个特征,可以如下图表示:
多变量梯度下降算法

特征缩放
样本的所有特征在相似的范围时,梯度下降算法有更快的收敛速度。
改变输入变量的范围,使其满足所有特征在相似的范围,通常情况为: or 。一般采用均值归一化实现特征缩放。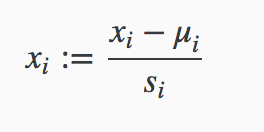
其中,$u_i$表示特征$(i)$的均值,$s_i$ 通常为 特征$(i)$中(最大值 - 最小值) 或者 特征$(i)$的标准差,一般使用(最大值 - 最小值)就可以满足了。
学习速率$\alpha$
学习速率$\alpha$影响代价函数收敛的速度,$\alpha$过小会导致收敛很慢,$\alpha$太大又会导致不收敛。
多项式回归
多项式回归能够使用线性回归的方法来拟合非常复杂的函数,甚至是非线性函数。其主要思想是变量替换。
如,
令 ,
则 。
标准方程
标准方程提供了一种求解$\theta$的解析解法。
设计矩阵X
具有n个特征的训练样本集(样本数量为m),构造设计矩阵$X$, $X$为 m*(n+1) 的矩阵
求解$\theta$, 。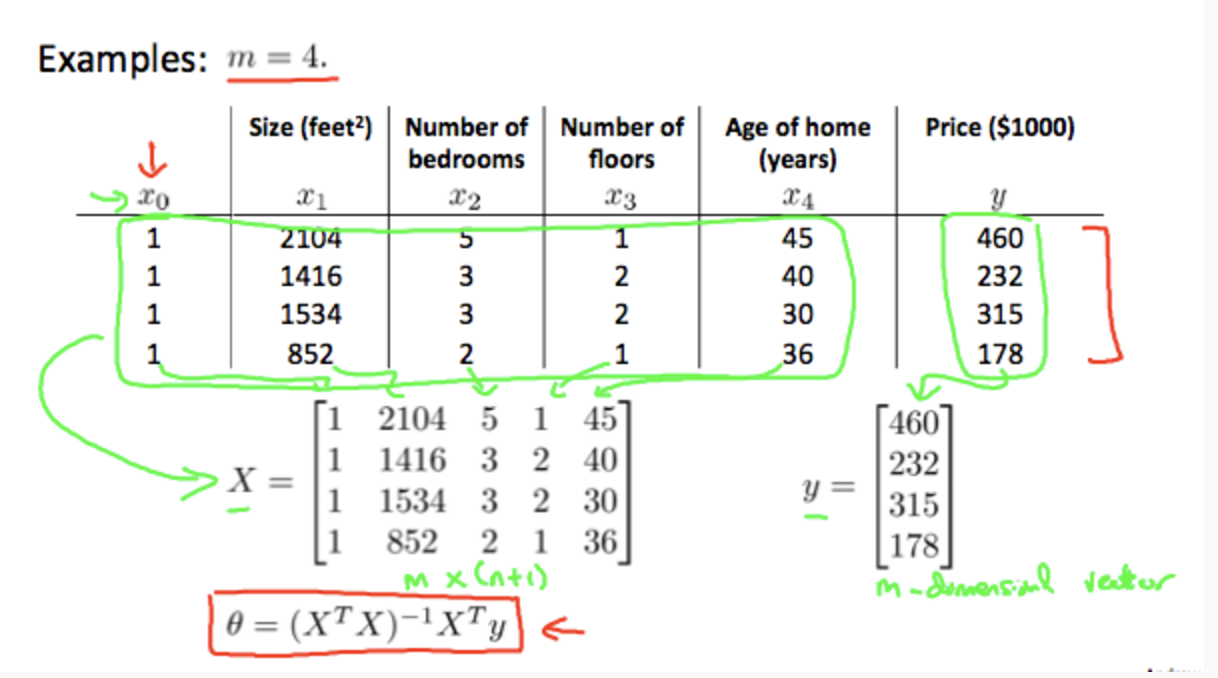
梯度下降算法和标准方程对比
| Gradient Descent | Normal Equation |
|---|---|
| Need to choose alpha | No need to choose alpha |
| Needs many iterations | No need to iterate |
| , need to calculate inverse of | |
| Works well when n is large | Slow if n is very large |