Celery 是一个异步的分布式任务队列,主要用于实时处理和任务调度。不过它的消息中间件是默认选择使用 rabbitmq。
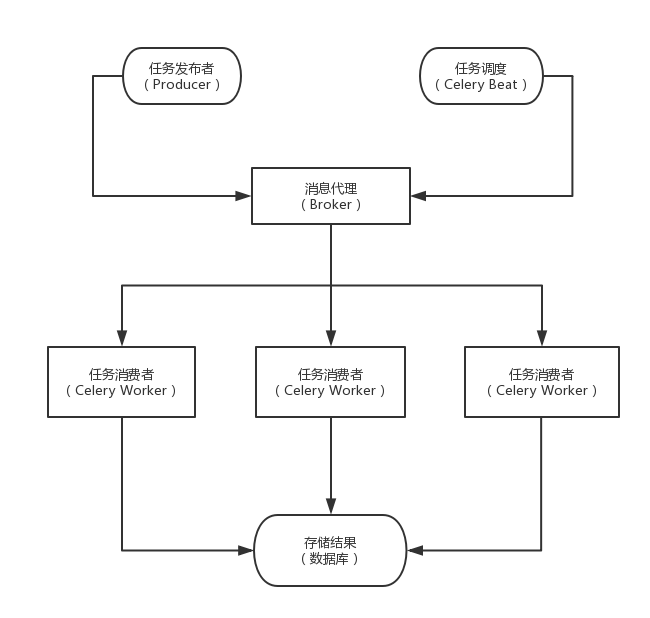
Celery 包含的组件:
- Celery Beat: 任务调度器,用来调度周期任务。
- Producer: 任务生产者,调用 Celery 产生任务。
- Broker: 消息中间件,任务消息存进队列,再按序发送给消费者。
- Celery Worker: 执行任务的消费者,通常可以进行在多台服务器上运行多个消费者。
- Result Backend: 任务处理完成之后保存状态信息和结果,一般是数据库。
Celery 产生任务的方式有两种
- 发布者发布任务
- 任务调度按时发布定时任务
Celery 的架构
样例
- Requirement
- Python 2.7.12
- pymongo>=3.5.1
- celery[msgpack]>=4.1.0
文件配置和常见结构一致,相关配置均在celeryconfig,py文件中,处理的任务中有一个定时调度任务feeddog, worker任务eat, feeddog任务中调度eat任务去执行,feeddog可以作为中心节点管理,而eat任务可以作为分布式节点去执行。celeryconfig中单独配置了eat任务的存储后端。
- app.py
1 | from __future__ import absolute_import |
- tasks.py
1 | from __future__ import absolute_import |
- celeryconfig
1 | #!/usr/bin/env python |
Run:
1 | # 分布式端点 |
在上面的自动调度方案中,是通过在配置文件中设置调度的相关参数,除了这种方式外还可以在代码里面设置,这种方式控制的粒度更为精细
1 | # @app.on_after_configure.connect not work |
工作流(canvas)
子任务:也可以视为一种任务,但如果把任务视为函数的话,它可能是填了部分参数的函数。子任务的主要价值在于它可以用于关联运算中,即几个子任务按某种工作流方式的定义执行更为复杂的任务。
Celery工作流包含以下原语:
- group
group并行的执行一系列任务:
1 | from celery import group |
- chain
chain串行的执行任务:
1 | from celery import chain |
- chord
chord是包含回调的group操作
- map
- starmap
- chunks
backend 使用rabbitmq
Celery 4.0以后backend使用rabbitmq推荐使用rpc, RPC Result Backend有如下特点:
- 默认不持久化, 可以通过配置 result_persistent来配置持久化
- 优势在于可以实时的获取状态变化,而不用客户端去轮询的获取
- 缺点: 只能被检索一次,如果您有两个进程等待相同的结果,其中一个进程将永远不会收到结果
worker 后台运行
celery multi命令在后台启动一个或多个worker。
1 | celery multi start w1 -A proj -l info |
supervidor
- celery.ini
1 | [group:test_celery] |
简单说明
- test_celery.async 和 test_celery.beat 是两个program,分别对应worker和beat,而它们又同属于 test_celery 这个组,这样便于同时管理。
- environment 下设置 PYTHONPATH